

Introdução
O APEX fornece dois recursos, fontes de dados REST e SQL habilitado para REST , que permitem acessar dados de outros sistemas via REST. Além disso, esses recursos permitirão que você use os resultados de forma declarativa em muitos componentes do APEX, como relatórios interativos, grades interativas, gráficos, lista de valores, etc.
A capacidade de obter dados em tempo real de outros sistemas é fantástica. Na maioria dos casos, isso elimina a necessidade de integrações dispendiosas.
Dito isto, se você usar excessivamente as chamadas REST em suas páginas APEX e não considerar o desempenho, isso apresentará problemas de desempenho. Mesmo a chamada de serviço REST mais rápida levará cerca de 0,25 segundo se você levar em consideração o seguinte:
- O tempo que leva para chamar o serviço REST (rede)
- O tempo que leva para executar a API por trás do serviço REST
- O tempo que leva para receber a resposta (rede)
- O tempo que leva para analisar e processar a resposta
Neste post, discutirei estratégias para melhorar o desempenho ao chamar serviços REST do APEX. Essas estratégias incluem sincronização de fonte REST e armazenamento em cache. Descreverei cada estratégia com o seguinte caso de uso.
Caso de uso
Em 2021, mudei-me para San Diego e queria saber quando o nível das marés estava baixo o suficiente para caminhar na praia. Foi nessa época que os PWAs foram introduzidos no APEX 21.2. Então, pensei em criar um aplicativo APEX para obter os níveis atuais e previstos das marés. Descobri que a Administração Nacional Oceânica e Atmosférica (NOAA) tinha vários serviços REST , que me forneceriam os dados que eu precisava.
Especificamente, os seguintes serviços REST:
- Locais (lista de estações de monitoramento)
- Previsões de marés (previsão dos níveis de maré para um determinado local)
- Nível da água (o nível atual da maré em um determinado local)
Incluí uma captura de tela (abaixo) do aplicativo que criei. Isso me ajudará a visualizar como uso os três serviços REST da NOAA.
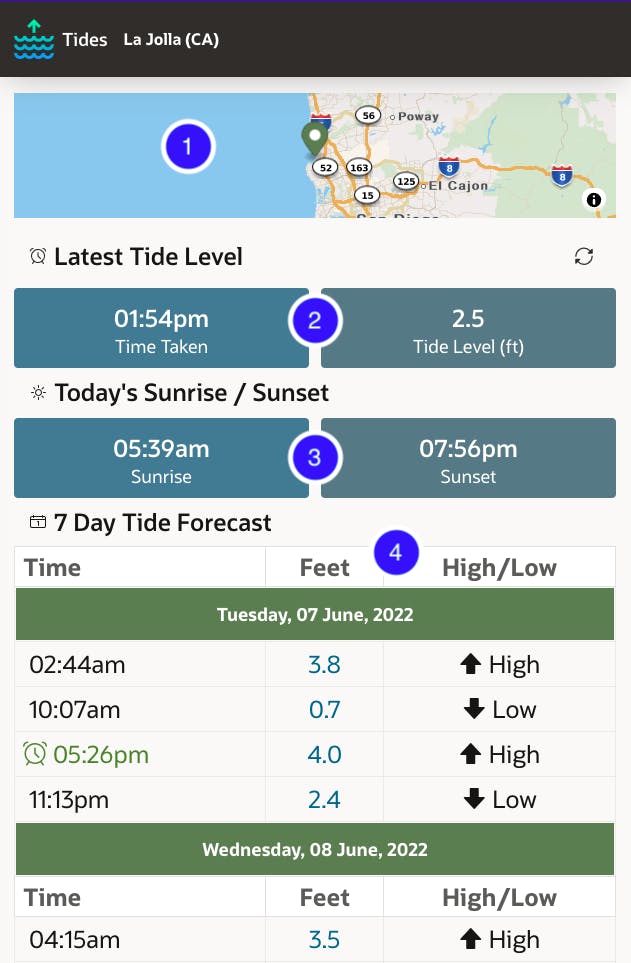
A captura de tela destaca as seguintes informações:
- Um mapa do local selecionado (do serviço REST de locais)
- O 'último nível da maré' (do serviço REST do nível da água)
- 'Nascer/Pôr do sol de hoje' (de api.sunrise-sunset.org - não discutido na postagem do blog)
- A 'Previsão de 7 dias' (do serviço REST de previsões de marés)
Você pode experimentar o aplicativo aqui
📥 Você pode baixar o aplicativo aqui . O App foi criado em APEX 22.1.
Criando fontes de dados REST
Comecei criando uma fonte de dados REST para cada serviço web NOAA. Não abordarei como criar fontes REST nesta postagem, mas discutirei algumas configurações posteriormente.
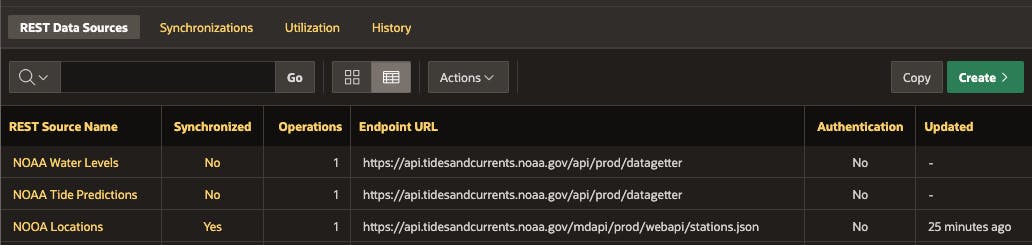
A criação das fontes REST ficou mais fácil porque nenhuma das APIs exige credenciais. Dito isto, as credenciais da Web APEX facilitam a criação e o gerenciamento de credenciais de serviços da Web.
Vale a pena fazer uma pausa aqui para discutir credenciais da Web e cache de token OAuth2. Se você usar fontes REST em componentes nativos do APEX ou chamar APEX_WEB_SERVICE.MAKE_REST_REQUEST , o APEX armazenará em cache os tokens OAuth2. Quando você chama um serviço web seguro, o APEX primeiro chama o URL do token associado à credencial da web e armazena em cache o token e a expiração. O APEX só chamará o servidor OAuth para obter um novo token quando o token atual expirar. Isso economiza uma viagem de ida e volta ao servidor de autenticação para cada chamada de serviço da Web feita para um terminal seguro.
Depois de instalar as fontes de dados REST, pude incorporá-las diretamente em meu aplicativo. Antes de fazer isso, precisei parar e considerar o desempenho.
Considerando o desempenho em tempo de design
O desempenho deve ser considerado durante o design do aplicativo (assim como a segurança e os requisitos). Por esse motivo, precisei considerar como usaria cada um dos três serviços web da NOAA.
Localizações
Rapidamente percebi que o serviço web Locais (estações de monitoramento) seria o mais usado. Os usuários precisam selecionar um local antes de poderem fazer qualquer coisa, e quero mostrar as informações do local em cada visualização de página. A lista de locais é relativamente estática e é atualizada diariamente, no máximo. Conclusão : armazene os locais localmente e sincronize-os com o serviço web NOOA todas as noites.
Previsões de marés
Como o nome indica, o serviço Tide Predictions fornece dados de previsão, portanto não precisamos buscar dados da fonte para cada visualização de página. Conclusão : ligue para o serviço web NOAA uma vez por hora e armazene a resposta em cache localmente pelo restante da hora.
Nível de água
A API Water Level busca o nível atual da maré, portanto, precisamos ver sempre o valor mais recente. A carga útil é pequena (apenas o nível da maré) e o serviço web é rápido. Conclusão : busque o valor mais recente do serviço da web NOAA sem armazenamento em cache.
Implementando os três serviços REST
Esta postagem pressupõe que você esteja familiarizado com fontes de dados REST e não abordarei sua criação em detalhes aqui.
Locais usando sincronização REST
A sincronização REST permite configurar sua fonte REST para chamar periodicamente seu serviço REST relacionado e sincronizar o resultado com uma tabela de banco de dados local. Você pode então usar essa tabela em seu aplicativo APEX com latência zero. Você deve identificar uma coluna de chave primária no 'Perfil de dados' da fonte REST (durante a criação da fonte REST). Identifiquei a coluna 'id' como a chave primária na imagem abaixo. A coluna da chave primária também deve ser a chave primária na tabela de sincronização local.
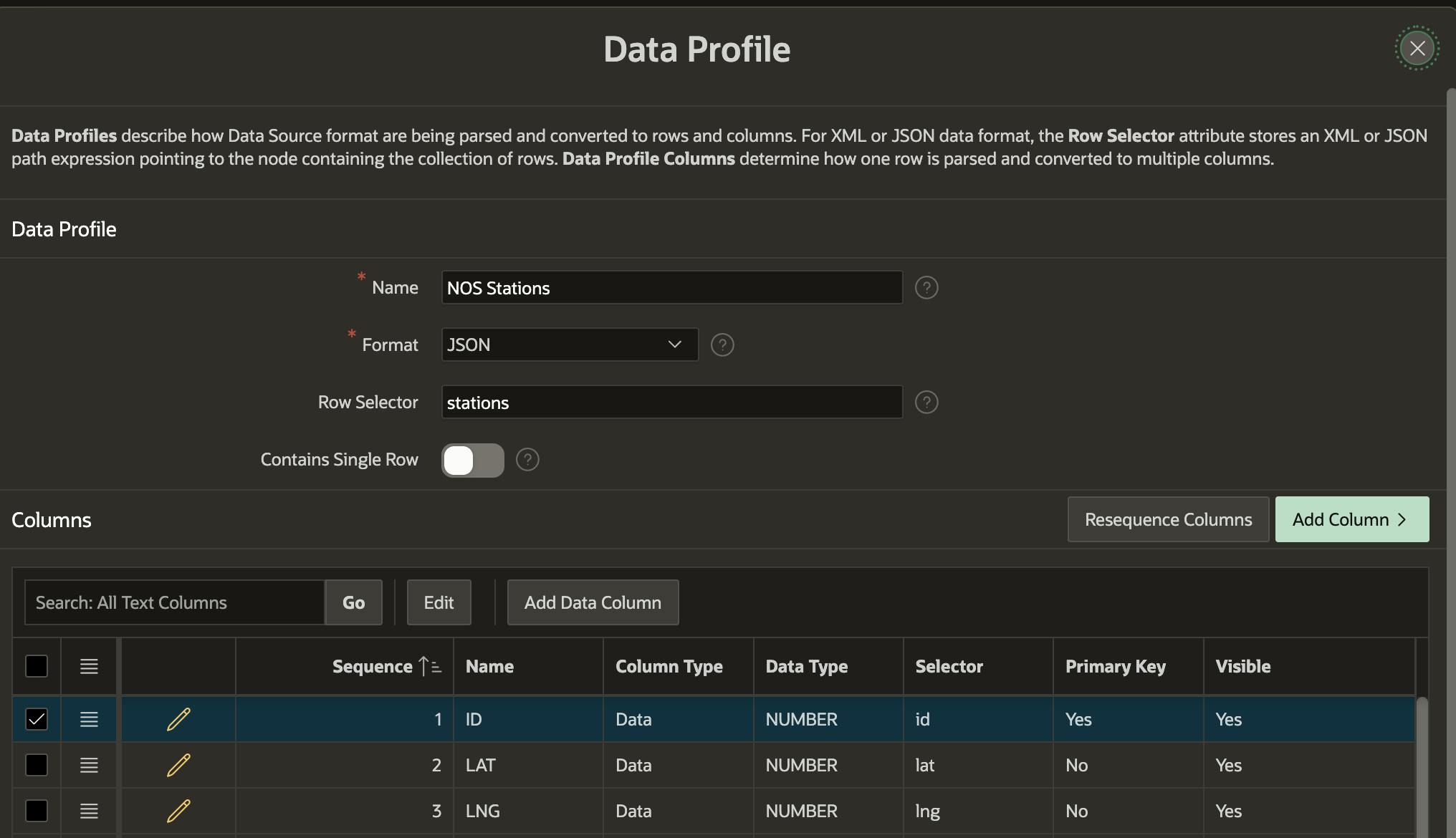
Depois de criar (e testar) a fonte REST, você pode clicar em ‘Gerenciar sincronização’ no lado direito.
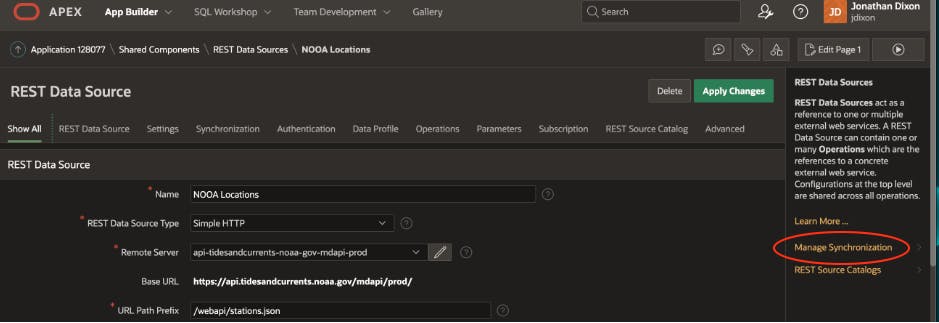
O APEX então abre a página de configuração abaixo e pergunta se você deseja criar uma nova tabela local para sincronizar ou se pode identificar uma tabela existente. Depois disso, você pode configurar as opções restantes de sincronização REST. Não entrarei em uma discussão sobre as configurações, mas gostaria de abordar algumas das opções essenciais abaixo.
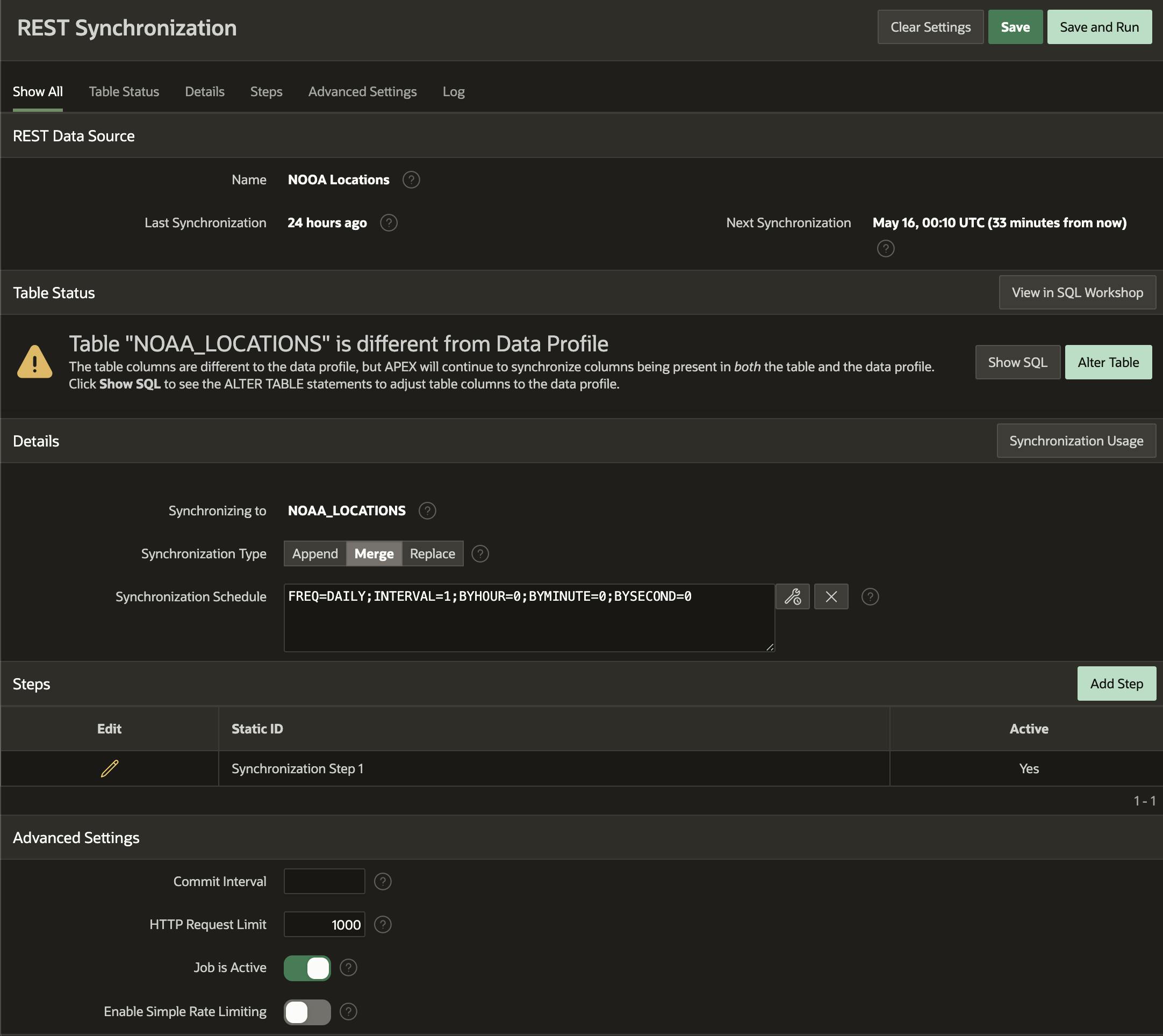
Status da tabela Se você selecionar uma tabela existente para sincronização, o APEX comparará as colunas dessa tabela com sua definição de dados de origem REST. Se encontrar alguma diferença, ela será destacada aqui. Ele ainda fornecerá um script para alterar sua tabela para corresponder à definição de dados de origem REST. Se você optar por sincronizar com uma tabela existente, sempre verá uma discrepância (mesmo que as colunas da tabela correspondam às colunas do perfil de dados de origem REST). Isso ocorre porque o APEX adiciona algumas colunas extras para rastrear a sincronização. Nota : Você não precisa dessas colunas extras para que a sincronização REST funcione.
Quaisquer colunas no perfil de dados de origem REST que não estejam na tabela local serão ignoradas. Você pode até ignorar colunas específicas marcando-as como 'Ocultas' no perfil de dados.
Tipo de sincronização Esta opção determina o que o APEX fará com as linhas existentes quando a sincronização for executada:
- Anexar: acrescenta linhas à tabela local. Normalmente é usado quando nenhuma chave primária foi definida no perfil de dados.
- Mesclar: Mesclar linhas na tabela local. O perfil de dados deve ter uma chave primária definida para usar esta opção. Se existir uma linha para o valor da chave primária fornecido, a linha será atualizada. Caso contrário, a linha será criada.
- Substituir: Esvazie a tabela local antes de carregar novos dados.
Agendamento de sincronização Você pode definir um agendamento usando a mesma sintaxe de calendário DBMS_SCHEDULER usada pelas Automações APEX . Isso permite que você decida com que frequência deseja que a sincronização seja executada. Optei por sincronizar diariamente à meia-noite UTC para sincronização de locais.
Configurações Avançadas Se você está preocupado em sobrecarregar o terminal REST, você pode implementar uma limitação de taxa simples usando a opção 'Habilitar Limitação de Taxa Simples'.
Uma palavra sobre paginação A maioria dos serviços REST limita o número de linhas que retornarão em uma solicitação. Isso reduz a carga no servidor que hospeda o serviço REST e fornece blocos de dados mais fáceis de consumir para o consumidor. Você pode especificar quantas linhas deseja que sejam retornadas em cada página até um máximo definido pelo proprietário do serviço REST. Se houver mais linhas para mostrar, elas incluirão links no final da resposta para o conjunto de linhas seguinte e anterior. Isso representa um pequeno desafio para uma sincronização automatizada de dados, pois você deve percorrer todas as páginas para obter os dados. Se o serviço REST for um serviço ORDS, o APEX terá cobertura e a sincronização REST percorrerá automaticamente todas as páginas. Desde o APEX 20.2, a Oracle introduziu suporte para outros esquemas de paginação simples. Isso inclui o tamanho da página e o deslocamento de busca, o tamanho da página e o número da página. Você também pode adicionar esquemas de paginação personalizados por meio de plug-ins do conector de fonte de dados REST.
Monitorando sincronizações REST
Cada vez que uma sincronização de origem REST é executada, as mensagens são registradas na tabela 'apex_rest_source_sync_log'. Os logs são visíveis na página Sincronização de Fonte REST (na parte inferior da página).
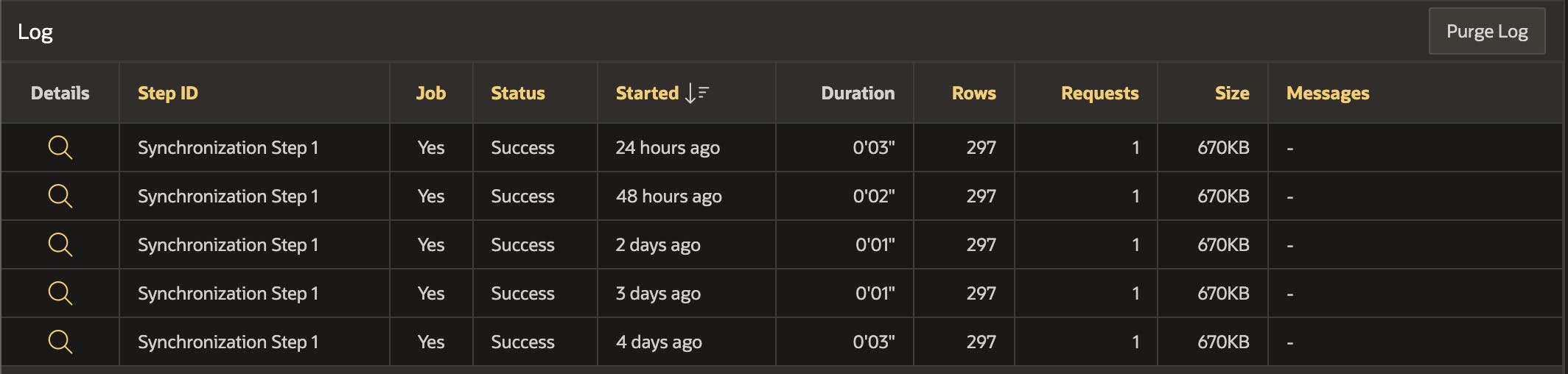
O SQL a seguir também pode ser usado para listar as fontes REST do seu aplicativo e mostrar a última vez que a sincronização foi executada e seu resultado.
WITH last_run AS
(SELECT alog.rest_source_id
, alog.status
, alog.rows_processed
, EXTRACT(minute from end_timestamp - start_timestamp) duration_minutes
, EXTRACT(second from end_timestamp - start_timestamp) duration_seconds
FROM apex_rest_source_sync_log alog
WHERE synchronization_run_id = (SELECT MAX(alog1.synchronization_run_id)
FROM apex_rest_source_sync_log alog1
WHERE alog1.application_id = alog.application_id
AND alog1.rest_source_id = alog.rest_source_id))
SELECT aapp.application_name
, module_name
, module_static_id
, sync_type
, sync_table_name
, last_synchronization
, last_run.status last_run_status
, last_run.rows_processed last_run_rows
, last_run.duration_minutes last_run_mins
, last_run.duration_seconds last_run_secs
, credential_name
, data_profile_name
, credential_name
, url_endpoint
, auth_url_endpoint
, next_synchronization next_sync
, sync_is_active
, sync_table_owner
FROM apex_appl_web_src_modules aawsm
, apex_applications aapp
, last_run
WHERE aawsm.application_id = aapp.application_id
AND aapp.application_id = <APP_ID>
AND aawsm.module_id = last_run.rest_source_id (+)
ORDER BY aawsm.module_name;
OK, isso é tudo para o serviço de localização e sincronização REST, agora vamos passar para o serviço de previsão de marés e falar sobre cache.
Previsões de marés usando cache de origem REST
Se você ativar o cache para uma origem REST, a resposta do serviço REST será armazenada em cache em uma tabela local. Isso é importante porque as chamadas subsequentes ao serviço da Web usarão a resposta armazenada em cache localmente, em vez de fazer a viagem de ida e volta ao serviço da Web. Um serviço REST de alto desempenho (em uma rede rápida) pode fornecer uma resposta em frações de segundo. Em vista disso, o cache pode não parecer grande coisa. No entanto, como a maioria das fontes REST não são tão rápidas e você pode chamar 2 ou 3 serviços REST para cada visualização de página, em breve poderá adicionar um ou dois segundos a cada visualização de página se não usar o cache.
O cache de origem REST é configurado na página de definição da operação REST Source 'GET'. Por razões óbvias, você não pode configurar o cache para operações PUT,POST e DELETE REST.
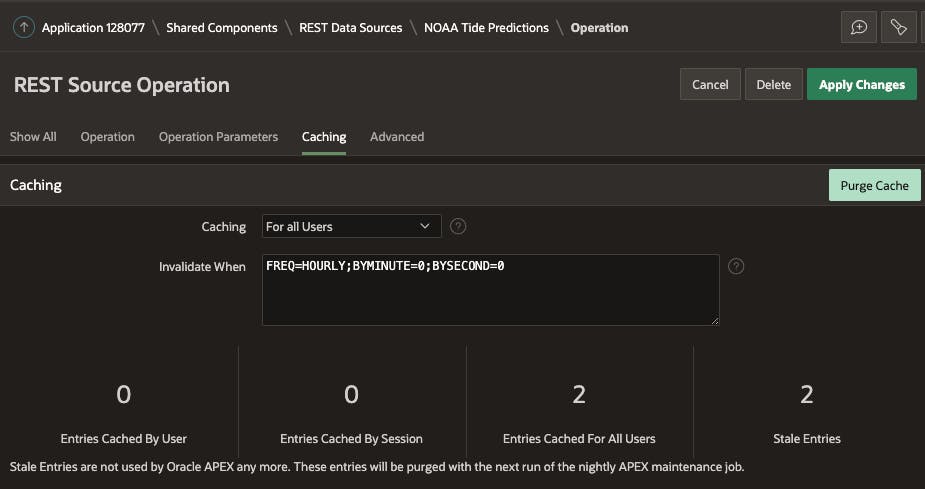
Você tem duas alavancas que pode usar para ajustar o cache:
Cache
- Desabilitado: o conteúdo não é armazenado em cache e obtido da origem REST para cada solicitação.
- Para todos os usuários: o conteúdo é armazenado em cache e utilizado por todos os usuários.
- Por usuário: o conteúdo é armazenado em cache especificamente para cada usuário.
- Por sessão: o conteúdo é armazenado em cache especificamente para cada sessão.
No meu exemplo, o conteúdo não é específico do usuário, então quero que o cache seja compartilhado por 'todos os usuários'.
Invalidar quando
Você pode usar a sintaxe de calendário DBMS_SCHEDULER para definir uma frequência de quanto tempo as cargas de resposta devem permanecer no cache local. No meu exemplo, estou invalidando o cache a cada hora. O motivo pelo qual desejo invalidar o cache a cada hora é forçar o APEX a buscar os resultados mais recentes do serviço da web e atualizar o cache.
Observação : toda a carga útil da resposta REST não analisada CLOB é armazenada no cache da tabela local, não nas linhas e colunas individuais. Isso significa que quando o APEX usa conteúdo armazenado em cache localmente, ele precisa analisar a resposta para usá-la em um componente do APEX. Não é uma grande sobrecarga, mas se você estiver unindo o conteúdo em cache a uma tabela local, poderá ver algum impacto no desempenho.
Como o APEX sabe se algo já está no cache? O APEX usa a URL (com parâmetros) da chamada ao serviço REST para determinar se já possui o resultado em seu cache.
Por exemplo. Supondo que você esteja começando sem nada no cache e faça uma chamada para a URL api.example.com/fetch_users?location= USA , o APEX chamará o serviço REST e armazenará a resposta em cache. Se você fizer outra chamada exatamente para o mesmo URL 5 minutos depois, o APEX perceberá que já possui a resposta em cache para esse URL e usará isso em vez de chamar o serviço da web novamente. Se 5 minutos depois você fizer uma chamada para o URL ligeiramente diferente api.example.com/fetch_users?location=UK , o APEX perceberá que não tem uma resposta em cache deste URL específico . O APEX chamará o serviço REST e armazenará em cache a resposta para esta URL, pronta para a próxima vez. As respostas armazenadas em cache permanecerão no cache local até serem apagadas com base no valor que você definiu no campo 'Invalidar quando'.
Níveis de água (sem cache)
Discutimos acima que queremos buscar o 'Último nível de maré' do serviço REST 'Nível de água' a cada visualização de página sem armazenamento em cache. Você pode pensar que isso tornaria esta seção da postagem do blog muito curta, mas ainda há coisas que você pode fazer para melhorar o desempenho.
Tamanho da carga Além da latência da rede, o tamanho de uma carga tem o maior impacto no desempenho quando se considera chamadas de serviço REST.
Uma grande carga útil:
- Demora mais para o serviço REST de destino processar e gerar a carga útil
- Demora mais para a rede ser transportada de volta ao APEX
- Demora mais para o APEX analisar e processar
O serviço REST 'Water Level' da NOAA possui parâmetros que permitem filtrar a resposta com base em data e hora de início e término. Se solicitarmos apenas os níveis de água dos últimos 10 minutos, obteremos 1 talvez 2 resultados. No exemplo abaixo, obtivemos uma resposta em 87 ms e o tamanho da carga útil é de apenas 783 bytes.
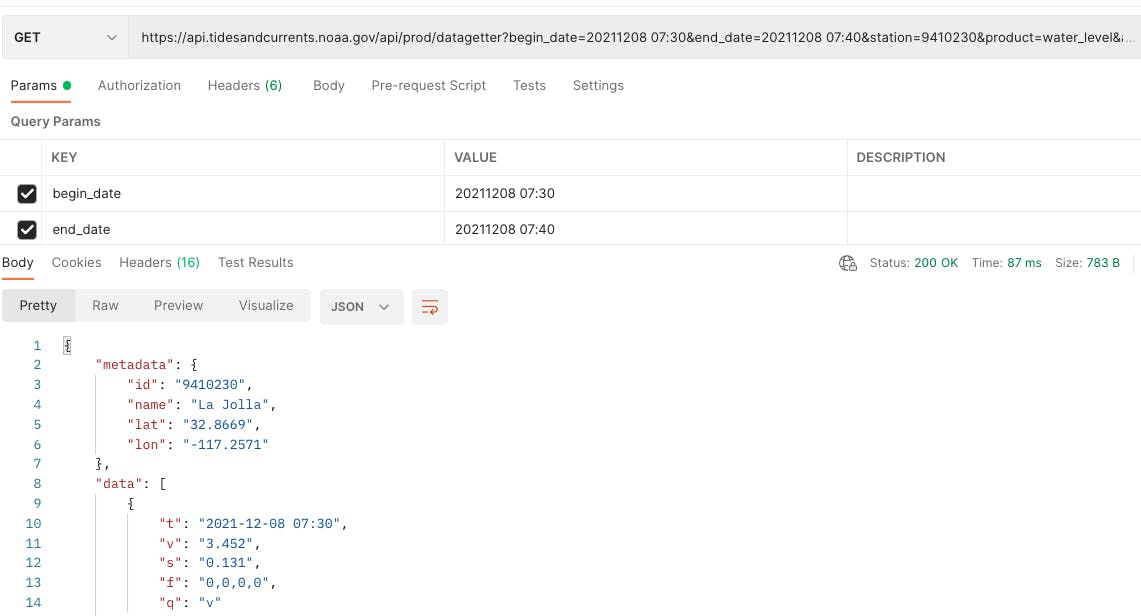
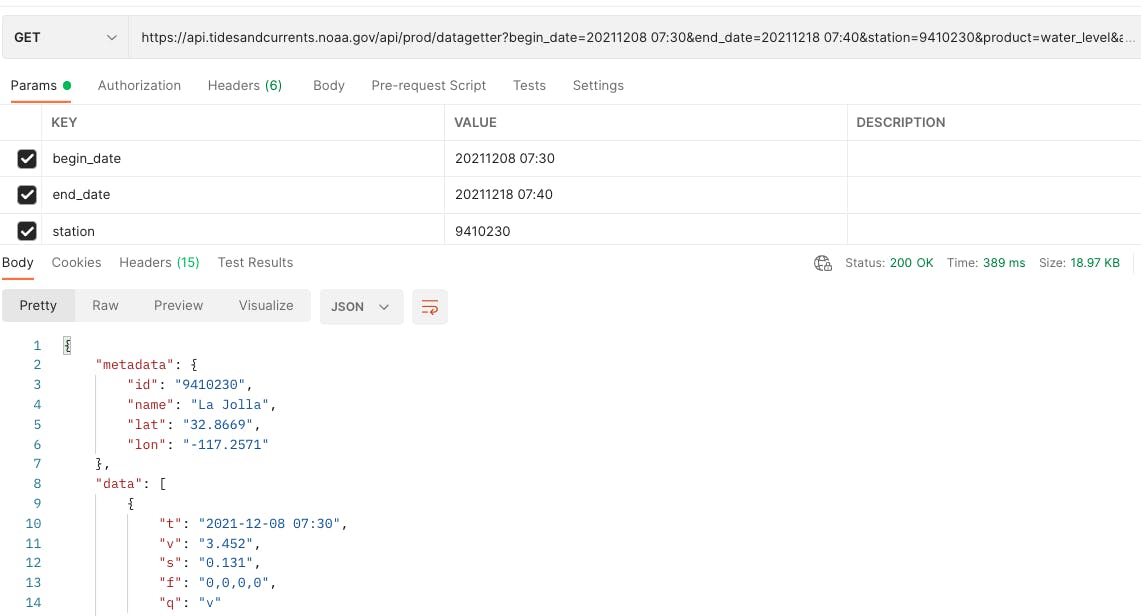
Além do aumento do tempo de resposta, também devemos considerar que o APEX levará mais tempo para analisar e filtrar a carga útil maior.
Método de análise Se você estiver usando fontes de dados REST do APEX, a análise será feita pelo APEX. Se você estiver chamando um serviço REST do PL/SQL, precisará considerar como analisar a resposta JSON. Se você ainda estiver usando APEX_JSON para analisar JSON em seu código PL/SQL, recomendo que pare. Leia minha postagem Para aumentar a velocidade, pare de usar APEX_JSON para saber mais sobre o porquê.
Se você estiver executando 12c (ou superior) do Oracle Database, a análise JSON nativa será muito mais rápida que APEX_JSON.
Conclusão
Pode parecer banal, mas o desempenho é uma jornada e não um destino. É fundamental dedicar algum tempo extra durante o projeto para considerar o desempenho e compreender quais opções de melhoria de desempenho estão disponíveis. Muitas vezes as pessoas dizem que preciso dos dados atuais/mais recentes sem compreender as implicações. Converse com seus usuários e analise os prós e contras dos dados em tempo real versus dados quase em tempo real. Por fim, entenda que mesmo quando o cache não é uma opção, isso não significa que não há nada que você possa fazer para melhorar o desempenho.
__________________________________________________
Fonte: John Dixon - Blog CLOUD NUEVA
Nenhum comentário:
Postar um comentário